How Google Ranks Web Pages – Part II: Unusual Suspects
In this part of the adventure we’re going to get into some of the not-so-common types of approaches Google might be using to rank web pages. The goal of this one, is to start your awareness about the sheer vastness of what we, as SEOs and marketers, are trying to pick apart. To broaden your thinking in ways you may not have considered previously.
I’d like you to start to get the mind-set of an engineer, to better attack the problems of our clients and our web sites. To never be locked in the box that is the world of cookie-cutter SEO.
As discussed in part I – we never ‘really‘ know what’s being used, how it’s being scored or what the thresholds may be. Ok? Great… thanks.
And away we go….
Search Presentation
While it doesn’t seem at intuitive as something along the lines of links, there are elements of how the results are presented that affects where something ranks. Let’s look at a few examples;
Grouping and presenting search query results – Where there is more than one result for a query, they might raise the rank of a lower page, up to the highest ranking page for a query for the sake of domain grouping. What that means in essence, is that if you have two documents returned for a result, one at position 3 and one at position 8, Google might re-rank the lower one, to be grouped with the higher one, (read the patent here).
Is this a traditional ‘ranking’ element? Nope. Would it have a greater affect on your results CTR? Your damned right. Consider this in your targeting, page mapping and content strategy approaches.
Here’s a 2013 Google video on ‘domain clustering’
;
Using web ranking to resolve anaphora – writers would know this one better. Anaphora is when we replace a given word that was used earlier in sentence, to avoid repetition and crafting a better sounding sentence. But how might Google use that in search results? I found an interesting patent here, that talks about;
“(…) receiving a first query; receiving a second query; analyzing the second query for a presence of anaphora; if an anaphora is present, analyzing the first query for a presence of an entity associated with the anaphora if at least two associated entities are returned from analyzing the first query for a presence of an entity associated with the anaphor, forming a third query wherein the anaphora of the second query is replaced with one of the at least two associated entities and forming a fourth query wherein the anaphora is replaced with the other of the at least two associated entities; sending the third query and the fourth query to a query-ranking engine; receiving a ranking for the third query and a ranking for the fourth query; and sending a higher-ranked query to a search engine. “
So, in this instance, Google might be (at the query level) adapting the search results in a predictive measure based on other similar queries and results. What we can take away from this, is an understanding that all impressions of our page in a search result, (ie; analytics) may not come from the term we were targeting. That the ranking (impression) can be ranked at the time of the query and the instance.
One example is a client of mine that get’s impressions/clicks for both these queries;
[do cold air intakes make a difference]
[do cold air intakes work]
The interesting part, is that the phrase “make a difference” is nowhere to be found on the page. In this instance, Google is using semantic analysis (potentially something like this patent being a part) to establish relevant queries for the landing page. Something we’ve talked about surrounding Hummingbird. Rank-adjusted content items – another interesting approach that might be in play is when rankings are adjusted based on a session. When Google is following a given search session, they might adjust the display based on what it feels the next query can benefit from. From this patent;
“(…) identification of a context of a search session facilitates the adjusting of a ranking of one or more content items in response to a search session query. The adjustment can, for example, be based on the likelihood that a current user is searching for the rank-adjusted content items because a statistically significant number of prior users that exhibited a similar behavior to the current user selected the rank-adjusted content items. “
Something such as this can help us to (among other things) better understand the fluctuations that might be present when looking at query data in Google analytics.
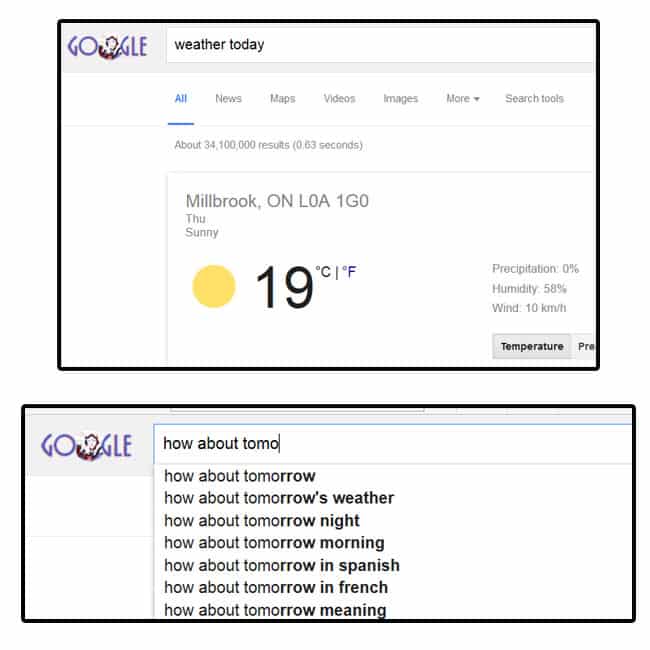
Ranking modifications of a previous query – in another implementation of query refinements and adjustments, Google may look at elements of the session to build out query refinements of expected related concepts and terms from the user’s query refinements. Such as this patent.
(…) modifications of a previous query may be generated based on a current query issued subsequent to the previous query. For example, the previous query may be [weather tomorrow] and the current query may be [how about on tuesday]. Modifications of the previous query may be generated by substituting the n-gram “tuesday” with each term of the previous query to form the modifications [tuesday tomorrow] and [weather tuesday]. Modifications of the previous query may additionally and/or alternatively be generated by substituting the n-gram “on tuesday” with each term of the previous query to form the modifications [on tuesday tomorrow], [weather on tuesday]. “
Something like this, can start to make us think of the future of elements such as “conversational search”, which debuted around the time of Humingbird.
When’s the last time you saw any of these concepts and considerations in an industry “ranking factors” post? Uh huh… hopefully you’re starting to see the madness that is my method. We can’t always lock ourselves into thought patterns that are limited to a small set of metrics.
Things You’ve Never Thought Of
In this section, I wanted to share a few of the more “out there” type approaches that Google might be looking at or using. I really want you to get past the TITLE tags, the links, the anchors and other commonly discussed ranking factors before we move on to the next part of the series.
Scoring site quality – many of us have talked about what an on-site quality score might look like, but really? What could it be? I tend to look at the Google Raters Guide as a good start, and then I found this;
“The site quality score for a site can be used as a signal to rank resources, or to rank search results that identify resources, that are found in one site relative to resources found in another site. “
In that instance, the QS could be used as another external signal, beyond links, as a scoring element. Which in itself, could be direct, or the more intangible EAT (expertise, authority, trust). In another implementation, some form of QS might be used for crawling and indexation….
“Alternatively, the site quality score for a site can be used as a signal in determining whether to crawl, refresh, or index a resource found in the site….”
And in another implementation, behavioural data might be used in a larger context to determine a score..
“ (Can) include the actions of obtaining a plurality of measurements of durations of user visits to resources included in a particular site; and determining a site quality score for the particular site based at least in part on the plurality of measurements, wherein determining the site quality score for the particular site comprises computing a statistical measure from the plurality of measurements. “
Which sounds all crazy, but it could be used in context of implicit user feedback (behavioural metrics) to establish a site or page quality score element. Again, the beauty of this is we don’t really know. But when attacking a problem, look beyond the common concepts of search engine optimization and marketing.
And to be honest? I believe this and other elements of the Google Raters Guide, does make for some form of Google Organic Site Quality Score. For more on the guide, feel free to watch this video we did last year on it.
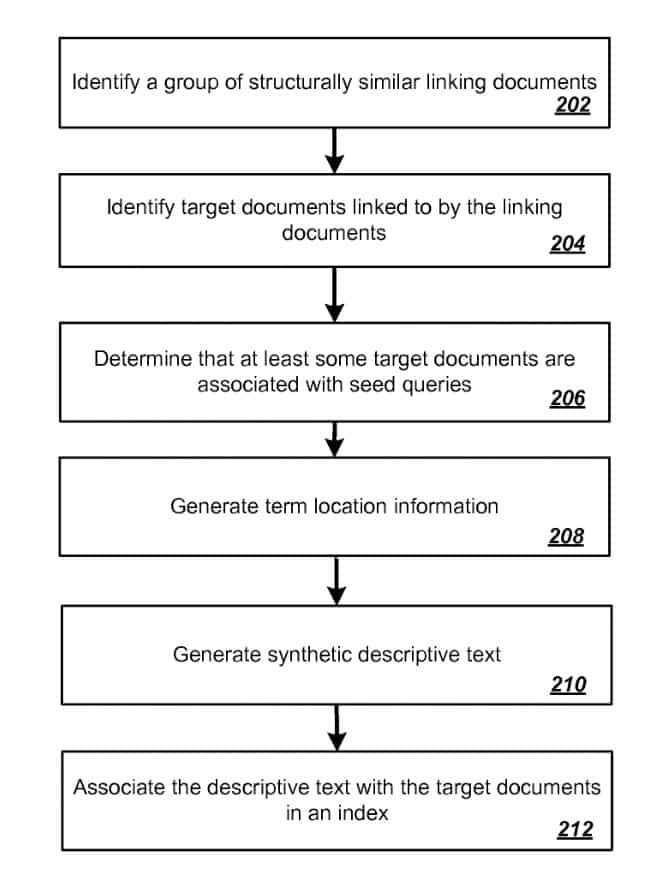
Descriptive text from an off-site resource. – and speaking of off-site scoring elements that aren’t links, another bit of an interesting approach I came across involved using non-link text (TITLE element, on-page text etc) to better understand a resource (page or site). Consider when you see something like “click here” in your anchor text reports. One approach Google could be using can be found in; Using synthetic descriptive text to rank search results
“(…) a particular search result resource of the plurality of search result resources is associated with one or more pieces of synthetic descriptive text, wherein each piece of synthetic descriptive text is generated by applying a respective template to a respective linking resource that links to the particular search result resource; “
From there they discuss, “adjusting the initial score for the particular search result resource based at least in part on the synthetic descriptive text score. “. Once again, not all scoring and adjusting (off-site) is based on links.
Code and resource optimization – what about not just the speed factor, but the actual data used to load the document? We’ve often told clients and others that it was a good idea to optimize code, especially since the rise of moblie. But has Google really looked at this? According to this patent, indeed they have.
They discuss “(…) ranking a search result document based on data usage required to load the search result document. “ – which certainly implies that the code size, resource optimization, might be important, not just the load times (although obviously related).
“(…) if the data measure of the first document is indicative of less data usage than the data measure of the second document, the ranking of the first document may be positively impacted and/or the ranking of the second document may be negatively impacted. In some implementations the ranking of a document may be based on determining an initial ranking of the document and modifying the initial ranking based on a data measure of the document. “
Are you still with me? I hope so. Once again, I want to express just a few approaches to get you thinking.
Getting Beyond The Accepted Thinking
And so, in this part of the journey we went beyond the commonly expected methods that Google could be using to rank web pages. A path that leads you to start to think about learning more about how things work within a search engine. An adventure beyond the cookie-cutter thinking that is “this thing of ours”.
In the next few instalments, we’re going to be getting into some of the more common ranking approaches that many of us know, or at least are aware of. Including;
Links
Behavioural metrics
Duplicate content
Geo-local
Semantic analysis
Recommendation engines
Categorizations and classifications
Temporal elements
Trust and authority
And more…
But… we’re going to dig in beyond the surface. My goal is to having you thinking far beyond the (black) box which is the standard industry thinking.
Until then? Some reading for the daring…

 When’s the last time you saw any of these concepts and considerations in an industry “ranking factors” post? Uh huh… hopefully you’re starting to see the madness that is my method. We can’t always lock ourselves into thought patterns that are limited to a small set of metrics.
When’s the last time you saw any of these concepts and considerations in an industry “ranking factors” post? Uh huh… hopefully you’re starting to see the madness that is my method. We can’t always lock ourselves into thought patterns that are limited to a small set of metrics.
 Code and resource optimization – what about not just the speed factor, but the actual data used to load the document? We’ve often told clients and others that it was a good idea to optimize code, especially since the rise of moblie. But has Google really looked at this? According to this patent, indeed they have.
They discuss “(…) ranking a search result document based on data usage required to load the search result document. “ – which certainly implies that the code size, resource optimization, might be important, not just the load times (although obviously related).
Code and resource optimization – what about not just the speed factor, but the actual data used to load the document? We’ve often told clients and others that it was a good idea to optimize code, especially since the rise of moblie. But has Google really looked at this? According to this patent, indeed they have.
They discuss “(…) ranking a search result document based on data usage required to load the search result document. “ – which certainly implies that the code size, resource optimization, might be important, not just the load times (although obviously related).
